HTTP
Follow this guide to set up and manage monitors using the Sentry API.
Sentry Crons allows you to monitor the uptime and performance of any scheduled, recurring job. Once implemented, it'll allow you to get alerts and metrics to help you solve errors, detect timeouts, and prevent disruptions to your service.
To begin monitoring your recurring, scheduled job:
- Create a new monitor in Sentry.
- Configure check-ins or a heartbeat for your job.
Optionally, you can skip the first step and create or update (upsert) a monitor through a check-in. See more below.
Check-in monitoring allows you to track a job's progress by completing two check-ins: one at the start of your job and another at the end of your job. This two-step process allows Sentry to notify you if your job didn't start when expected (missed) or if it exceeded its maximum runtime (failed).
SENTRY_INGEST="https://o0.ingest.sentry.io"
SENTRY_CRONS="${SENTRY_INGEST}/api/0/cron/<monitor_slug>/examplePublicKey/"
# 🟡 Notify Sentry your job is running:
curl "${SENTRY_CRONS}?status=in_progress"
# Execute your scheduled task here...
# 🟢 Notify Sentry your job has completed successfully:
curl "${SENTRY_CRONS}?status=ok"
If your job execution fails:
# 🔴 Notify Sentry your job has failed:
curl "${SENTRY_CRONS}?status=error"
If you expect your scheduled jobs to overlap, read about Overlapping Jobs below.
When sending check-ins to your monitor you may specify the environment of the check-in. This allows you to monitor a single schedule across multiple environments.
If you don't specify an environment with your check-ins the default is production.
Monitor environments are still early in development. Currently, after a check-in occurs for a specific environment, you must continue sending check-ins on schedule or delete the monitor environment; otherwise, it will be marked as missed.
SENTRY_INGEST="https://o0.ingest.sentry.io"
SENTRY_CRONS="${SENTRY_INGEST}/api/0/cron/<monitor_slug>/examplePublicKey/"
# 🟡 Notify Sentry your job is running in the dev environment:
curl "${SENTRY_CRONS}?environment=dev&status=in_progress"
# Execute your scheduled task here...
# 🟢 Notify Sentry your dev environment job has completed successfully:
curl "${SENTRY_CRONS}?environment=dev&status=ok"
Sentry enables the automatic creation or update of a monitor (upsert) through the check-in payload. This can be useful if you have many scheduled tasks or need to create them dynamically.
SENTRY_INGEST="https://o0.ingest.sentry.io"
SENTRY_CRONS="${SENTRY_INGEST}/api/0/cron/<monitor_slug>/examplePublicKey/"
# 🟡 Notify Sentry your job is running:
curl -X POST "${SENTRY_CRONS}" \
--header 'Content-Type: application/json' \
--data-raw '{"monitor_config": {"schedule": {"type": "crontab", "value": "0 * * * *"}}, "status": "in_progress"}'
Monitor monitor_config parameters:
schedule_type:
The schedule representation for your monitor, either crontab or interval.
schedule:
The job's schedule :
This is an object specifying a schedule_type of either crontab or interval. The structure will vary depending on the type:
{"type": "crontab", "value": "0 * * * *"}
{"type": "interval", "value": "2", "unit": "hour"}
checkin_margin:
The amount of time (in minutes) Sentry should wait for your check-in before it's considered missed ("grace period"). Optional.
We recommend that your check-in margin be less than or equal to your interval.
max_runtime:
The amount of time (in minutes) your job is allowed to run before it's considered failed. Optional.
failure_issue_threshold:
: The number of consecutive failed check-ins it takes before an issue is created. Optional.
recovery_threshold:
: The number of consecutive OK check-ins it takes before an issue is resolved. Optional.
timezone
The tz where your job is running. This is usually your server's timezone, (such as America/Los_Angeles). See list of tz database time zones. Optional.
It's important to provide a timezone for non-repeating crontab schedules, such as 0 17 * * * (every day at 5pm).
A job execution that begins before the previous job execution has been completed is called an overlapping job. This happens if you have a job with a runtime duration longer than your job's interval schedule.
A simple example is if you have a job that runs every minute (1), but takes five (5) minutes to complete each execution.
If this happens, you have to provide a stable check-in ID for your execution with each request to prevent unintended consequences.
Usage example:
CHECK_IN_ID="$(uuidgen)"
SENTRY_INGEST="https://o0.ingest.sentry.io"
SENTRY_CRONS="${SENTRY_INGEST}/api/0/cron/<monitor_slug>/examplePublicKey/"
# 🟡 Notify Sentry your job is running with a check-in ID:
curl "${SENTRY_CRONS}?check_in_id=${CHECK_IN_ID}&status=in_progress"
# Execute your scheduled task here...
# 🟢 Notify Sentry your job has completed successfully with a check-in ID:
curl "${SENTRY_CRONS}?check_in_id=${CHECK_IN_ID}&status=ok"
Heartbeat monitoring notifies Sentry of a job's status through one check-in. This setup will only notify you if your job didn't start when expected (missed). If you need to track a job to see if it exceeded its maximum runtime (failed), use check-ins instead.
SENTRY_INGEST="https://o0.ingest.sentry.io"
SENTRY_CRONS="${SENTRY_INGEST}/api/0/cron/<monitor_slug>/examplePublicKey/"
# 🟢 Notify Sentry your job has completed successfully:
curl "${SENTRY_CRONS}?status=ok"
If your job execution fails:
# 🔴 Notify Sentry your job has failed:
curl "${SENTRY_CRONS}?status=error"
When your recurring job fails to check in (missed), runs beyond its configured maximum runtime (failed), or manually reports a failure, Sentry will create an error event with a tag to your monitor.
To receive alerts about these events:
- Navigate to Alerts in the sidebar.
- Create a new alert and select "Issues" under "Errors" as the alert type.
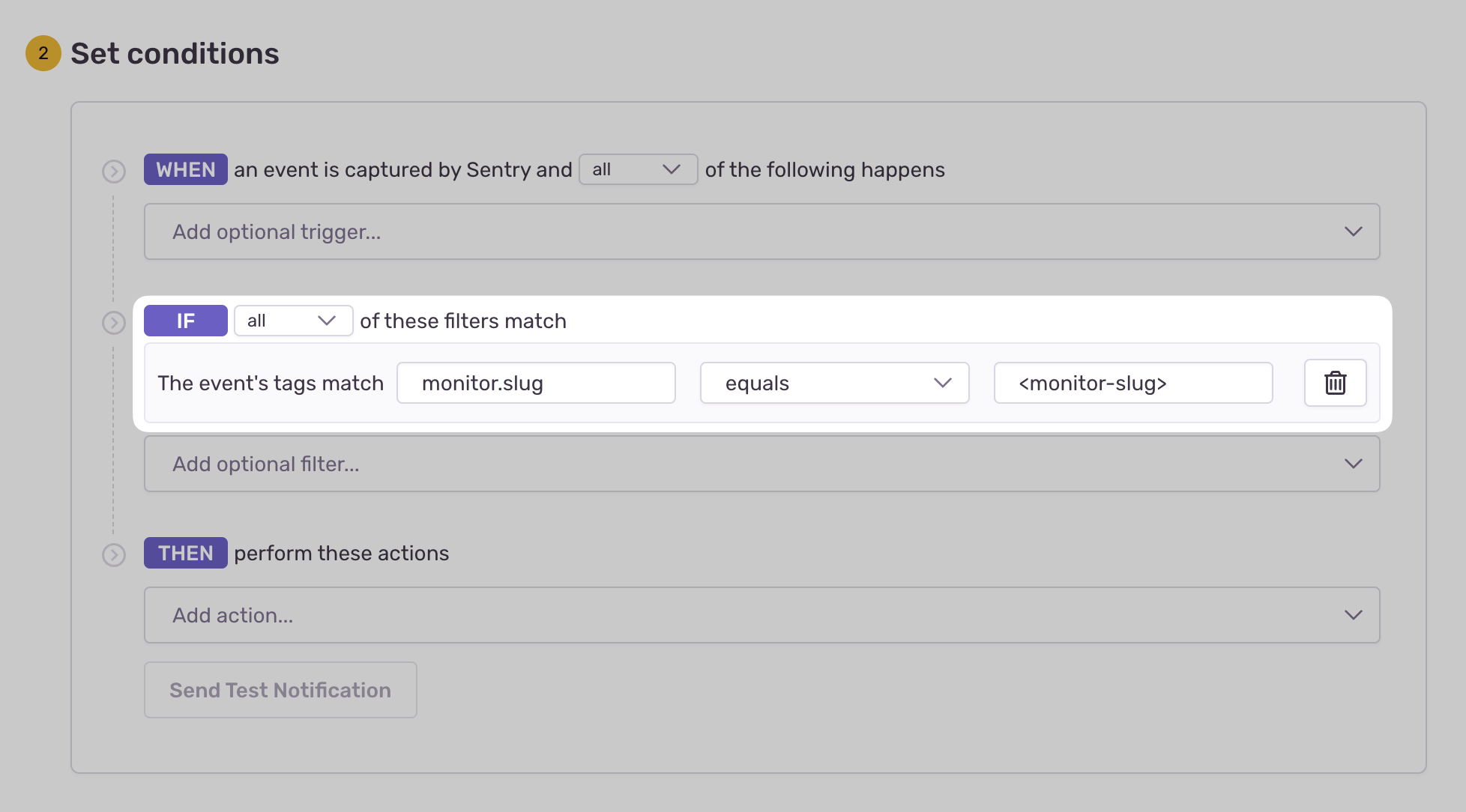
- Configure your alert and define a filter match to use:
The event's tags match {key} {match} {value}.
Example: The event's tags match monitor.slug equals my-monitor-slug-here
Learn more in Issue Alert Configuration.
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").